 服务热线:
服务热线:基于深度学习的猪胴体图像分级系统设计与实现
沈阳工业大学信息科学与工程学院 韩宏宇
信息来源:《肉类产业资讯》
发布日期:2021年第3期
发布日期:2021年第3期
《续》
第3章 猪胴体图片数据集的建立
目前世界上采用多层神经网络对肉类图像特征进行学习的研究成果不多,故当前国内外并没有有效的猪胴体图像数据库可供应用,另外由于肉猪种类的区别,不同国家地区的猪胴体分级标准有一定差别,从互联网上获取的猪胴体图片普遍存在拍摄角度、清晰度、光照条件、分类信息不明确等问题。本文主要针对在猪肉加工车间环境下猪胴体图像的学习和识别,为了支持研究中网络模型建立过程的进行,决定构建猪肉加工车间内的猪热胴体图像库。
3.1 猪胴体图像的获取
在本次研究中,选择了辽宁地区猪肉生产加工龙头企业之一的铁岭九星集团的猪肉屠宰加工生产线作为合作对象,其猪肉屠宰加工生产线为我国绝大多数猪肉加工企业所通用的半机械半人工加工平台,对国内的猪肉加工企业有较好的普适性。
通过与九星集团的沟通协调,在不影响生产的情况下,以固定距离和角度分多次拍摄了在生产线环境下的猪胴体原始照片共93张,包括猪左半胴体原始照片56张及猪右半胴体原始照片37张;93张原始照片中车间常规照明(白炽灯)环境下的猪胴体照片82张,闪光灯增亮环境下的照片11张。拍摄的93张照片分属于75个生猪个体,其中由人工判别后标定为I级的有52个,标定为II级的有21个,标定为III级的有个。
深度神经网络的训练需要大量的训练集,仅使用原始照片完全无法满足神经网络的训练及测试需要。为了保证神经网络能被充分训练,将93张原始照片进行数据增广,直接复制已有的样本添加入训练集中虽然可以扩大训练集,但大量重复样本训练的神经网络很容易出现严重的过拟合情况。故本文使用了一系列常用且符合研究要求的数据增强的方法来扩充样本集的大小。
(1)图像平移,在对猪胴体进行分级时,猪胴体在图片中的位置差别不影响猪胴体的分级结果,故采用图像平移的方法,通过对图像采取范围为10个像素点的随机平移。
(2)图像镜像,猪胴体分级过程中左半胴体图片和右半胴体图片可视为基本完全一致的镜像图片,故对图片进行镜像处理。
(3)增加图像噪声,通过对图像适当添加不同的椒盐噪音,使图片呈现更多的变化性。所谓椒盐噪音,就是在图片上随机添加白色或黑色的点,其中添加噪声为白色的(白色点灰度值为255)称为盐噪音,而添加噪声为黑色的(灰度值为0)称为胡椒噪音。椒盐噪声本身不会影响图片的轮廓和纹理特征,是扩大图片类数据集的一种有效方式。
以上操作均通过Visual Studio2015及OpenCV3.1利用C++语言批量完成。数据增广范例如图3.1所示。通过多种数据增强的方法后,猪胴体图像数据集的带标签图片数量达到了16000余张,可以满足网络训练和测试的要求。
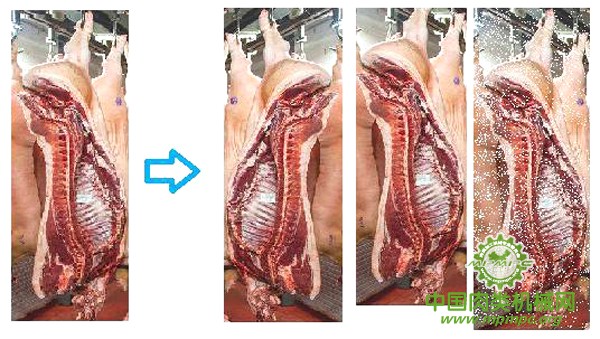
图 3.1 数据增广的三种方法(分别为图像镜像、图像平移、增加噪声)
每张图片的文件名作为这张图片的标签,其格式如图3.2所示,其中数据类型代表其为训练集或测试集;品级信息代表其人为判别品级,为了未来对数据集的进一步拓展,保留了一个待拓展位。
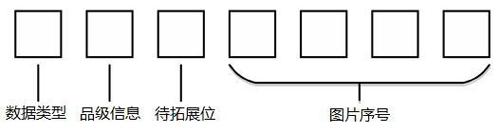
图 3.2 猪胴体图片文件名格式
除调用SMOTE算法包及PCA/ZCA白化算法包以外,猪胴体图像数据集构建过程的程序流程图如图3.3所示。
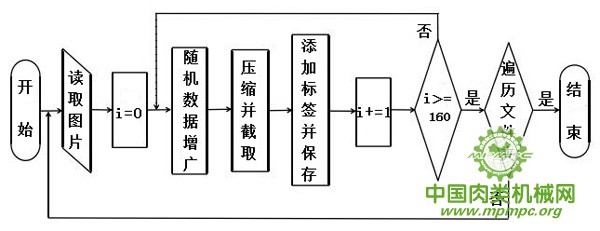
图3.3构建猪胴体图像数据集程序流程图
3.2 数据集不平衡问题的解决
由于生猪饲养技术的不断提高,大多数生猪的猪胴体品级均为I级,少数生猪会有II级的评级,而评级为III级的猪胴体在大规模生猪饲养的环境下几乎不存在。对于生猪养殖和猪肉加工企业而言,这是行业的进步,但在神经网络的训练中,由于相差过大的样本比例,极大地增加了类别数据的不均衡性。
分类任务需要对数据进行处理,但是在分类时不平衡的情况时有发生,不同类别的数据差距不一,例如在一个具有两种类的数据集中有200个样本,其中多数类A中有160个样本,而少数类B中的样本数量为40个,那么两类的比例就是4:1,样本数量呈现一种不平衡的状态。类别不均衡是几乎所有分类工作中或多或少都会出现的广泛问题,例如在对数据进行分析识别商业诈骗的工作中中,属于商业诈骗的例子明显只会占整体数据极小的一部分,即绝大部分的记录都是诚信的。
数据分类不平衡的情况总会时不时的出现,如果在二分法中的数据差距比例超过4:1,那么就会对数据本身造成一定的影响,如果在分类之前不对这样的数据进行处理,那么数据不平衡将会向数据错误进行转变,造成更严重的后果。例如在客户服务调查中,90%的客户想要继续合作,而只有10%的客户不想继续合作,那么在客户合作方面的比例就会严重失调,差距较大就会造成之后的数据处理时忽略较小的一部分而使得整体的分类产生错误。
通过训练集和算法可以一定程度上改善数据在分类时产生的不平衡问题。改变训练集中的数据分布或者学习一个新的算法等等的办法都可以在数据处理时实时的纠正即将产生的错误。重采样、学习算法或者改变分类依据来保证正确率的提升。
重采样(resampling)包括两种方法,包括对整体数据集进行扩大的上采样(过采样)方法以及缩小数据集的下采样(欠采样)方法,两种方法的目的都是使原本相差较大的不均衡类更加均衡,避免不均衡数据导致的对少数类判断错误率过高等问题。其中上采样扩大了少数类样本的数量,其具体实施方法有很多,最简单的就是直接复制少数类的样本从而实现扩大少数类数量的效果,这个方法在实际应用中证明效果不佳,不能有效提升判别的正确率同时还会产生过拟合的隐患。针对这种情况,相关学者提出了一些更具实用性的上采样技术,通过对数据的判断与分析,对一些特定的少数类样本进行复制或按照原有少数类的规律生成新的少数类样本,本文采用的SMOTE算法就是一种实用性很强的上采样数据增加手段。下采样的策略与上采样策略相反,为了实现样本的均衡,下采样方法对多数类进行处理。简单的方法如随机删除存在着影响判断准确率的隐患,可能会丢失部分多数类的特征。在下采样方法的研究中,选择多数类中的非重要数据成为了算法改进的核心。
在实际生产生活中,各种分类活动其侧重点普遍在于提高对稀有类的划分与判断的准确率,对于稀有类的判断往往比对普遍类的判断更为重要。重采样方法作为解决数据集数据不均衡问题的重要方式,在其相关算法的研究发展中,上采样方法较下采样方法普遍更为实用有效,这与下采样方法的核心思想(缩小数据集)有关。在诸多上采样方法中,SMOTE(Synthetic Minority Oversampling Technique)算法由于其对数据集扩大过程中少量类的特征影响小、易于实施等优点广泛地被应用于许多存在数据类不平衡的情况。
SMOTE算法被发表于2002年,其要解决的核心目标就是对不均衡样本集中的稀有类进行有选择地扩大,使稀有类中数据的数量达到与普遍类中数据的数量接近的程度。SMOTE算法的基本思想是设训练集的一个少数类的样本数为T,那么SMOTE算法将为这个少数类合成NT个新样本。其中N是正整数,给定N<1,SMOTE算法将少数类的样本增广至T=NT,并将强制将N设置为1。该少数类的一个样本i,其特征向量为xi ,i∈{1,...,T}:
(1)从该少数类的全部T个样本中找到样本xi 的k个近邻(例如用欧氏距离),记为Xi(near) ,near∈{1,...,k} ;
(2)从这k个近邻中随机选择一个样本Xi(n,n),再生成一个0到1之间的随机数ζ1,从而合成一个新样本Xi1:Xi1 =Xi +ζ1×(Xi(n,n) ?Xi )。
将步骤2重复进行N次,从而可以合并为N个新样本:Xinew(new∈1...N)。对全部的T个少数类样本进行上述操作,便可为该少数类合成NT个新样本。以二维样本为例,如图3.4所示,原样本中少数类S的样本数较L类相差极多,其中L类样本6320例,S类样本680例,通过过采样中的SMOTE算法后,通过插值,将S类的样本数扩大到了3160例,经过SMOTE扩大后的样本类间的均衡性显著提高,深度网络的学习更准确更全面。且由于增广的样本是通过插值产生而非单纯的随机复制而来,在学习的过程中也可有效地避免过拟合情况的发生。

图 3.4 Smote 算法原理图及实际效果
3.3 针对深度学习的数据预处理
通过数据增广和SMOTE算法的处理之后,猪胴体图像数据集的数量和均衡性都达到了满足卷积神经网络训练的要求,但仍无法达到直接输入到卷积神经网络中进行学习的水平。
首先获得的猪胴体图像集的原图图像尺寸过大,虽然也可以输入网络中进行学习,但在有限的硬件条件下,过大的图片尺寸将极大地影响网络的学习效率和学习效果,假设用于学习的卷积神经网络采用四层卷积层的结构,同时采用尺寸为3×3的卷积核,那么一张尺寸为4000×3000的原图经过填充层填充后每层需要完成卷积计算4002(最接近且大于4000的3的倍数)×3000/(3×3)=133400次,而尺寸为100×75的压缩图经过填充层填充后每层仅需卷积计算102×75/(3×3)=850次卷积运算,单张图片仅在四层卷积层中需要多进行卷积计算(133400/800)倍,将消耗大量的计算能力和时间。同时过大的图片也将导致图片的特征过多,极易产生过拟合的情况。但同时,由于猪胴体分级信息的识别分类需要依靠一定程度的纹理细节,不能为了减少网络学习过程中的运算量而过度地压缩图片,导致脂肪与肌肉的相关纹理细节损失过大。
鉴于本次研究采用AlexNet,其标准网络输入图片尺寸为227×227,针对这个情况,对猪胴体图片压缩至336×336尺寸,然后选取图片正中的227×227部分图片作为数据集图片进行下一步处理。这样既可以更大地突出猪胴体部分的图片,同时对计算机运算量要求很少,有很快的响应速度,图片截取范例如图3.4所示。
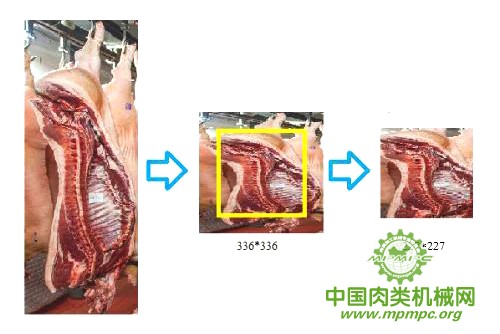
图 3.5 猪胴体图片压缩及截取示意图
对于猪胴体人工辨识分级的情况,颜色和纹理细节越详细,目视判别的准确率越高。但在卷积神经网络的学习中,丰富的色彩变化、显著的亮度差异以及三通道的颜色模式,其在数据层面上代表的是巨大的样本特征差异。这些均会在卷积神经网络进行学习的过程中导致特征值的过度分散,影响卷积神经网络学习过程中的收敛速度和效果。
所以在建立猪胴体图像数据集的过程中,需要对要经过深度学习的图像进行有针对性的数据预处理。
3.3.1 数据归一化
为了使网络模型可以更好地训练与识别,要对数据进一步进行归一化处理。数据归一化的方法有很多,具体方法通常是根据数据的实际情况而对应选择的。特征归一化常用的方法包含如下几种:
(1)特征值缩小
图片型数据由一个个的像素组成,在灰度图像中每个像素点的灰度值可以取0到255,分别对应黑色和白色,但这样的数据范围对于网络模型而言太大,波动性大的数据往往导致网络对数据的收敛能力减弱,导致模型拟合困难。对图片而言,可以用255对每个像素点的灰度值做除法,得到一个范围在(0,1)中的数,通过逐个像素点的运算,可得到整张图片的缩小化特征值。对于彩色图片同理,将RGB三个通道的对应数值分别除以255,并按照通道的不同分别进行存储。
(2)去均值化
对于较稳定的数据(不同特征向量的特征值分布相接近),可以根据特征值对整个样本取平均值,例如对一张灰度图片的每个像素点的灰度值取平均值,然后对图片中的每个像素点,均用该点的灰度值减去图片的灰度平均值,得到的样本空间更小,有利于拟合。
(3)特征标准化
这是一种广泛应用于实际数据处理中的归一化处理方法,其原理是使数据在不同的特征向量中呈现普遍的零均值与单位方差。特征标准化在实施时,对全部的样本集获取各特征维度的特征平均值,像去均值法一样从各个特征点中去除掉整体的平均值之后,用这个特征向量上样本的标准差除每个特征向量上的样本点。
3.3.2 PCA/ZCA白化
数据通过归一化处理后,以相对规整的形式进入接下来的白化处理环节,白化处理是许多现代多层神经网络模型能够高效稳定运行的重要因素。白化处理从根本上讲是一种降低维度的运算方法。其包括了PCA白化处理算法和ZCA白化处理算法。
(1)PCA白化
PCA(Principal Components Analysis)主成分分析算法本质是一种减少特征种类的算法。在无监督学习的过程中,若参与训练的样本包含了过多的特征种类,则这些特征种类中通常会有一部分特征值间具有关联。这些具有关联的特征有部分是可以用其他特征代替的,导致特征种类中产生了数据冗余,由于深度神经网络的训练和识别过程需要大量的迭代与运算,冗余的数据不仅严重影响网络训练和识别的速度,同时也会影响网络的拟合。
PCA算法通过获得数据集中的样本的特征均值μ,对样本中的数据进行去均值处理,并获得去均值后样本的协同方差矩阵。根据该矩阵获得其特征值以及特征值对应的维度;将维度翻转后,对数据集中的各个样本进行翻转维度的比对;将对应关系中数值小的部分去除,实现数据的降维。而PCA白化则是在PCA算法的基础上对获得的特征向量逐个进行标准差的除法,通过对标准差的除运算后,样本中每个特征向量的方差均为1。
(2)ZCA 白化
PCA操作主要实现了减少特征向量的目的,而ZCA操作则更多地面向去除维度间的相关性方面。ZCA的实质是在不去除样本的特征向量个数的情况下完成部分PCA的步骤,其主要目的在于消除特征向量间的联系,让特征更有“特征”且与最初的样本更加类似。
(3)白化参数的确定
要对数据进行有效的白化,需要确定进行白化时的ε参数。通过对样本采用ZC方法,进行了ZCA的样本若在图像化状态中有大量的噪点存在,则说明ε的选择偏小;若ZCA后的样本的特征值图像出现“长尾”,则表示ε的选择偏大。白化的本质在于选择合适的参数进行低频滤波。
3.4 数据集二进制化
为了方便未来对猪胴体图像在深度学习领域的进一步研究,本文中参照CIFAR-10这一广泛使用的图像数据集格式,将经过预处理的猪胴体图像数据集制成了二进制图像数据集。
CIFAR-10是由Alex Krizhevsky和Ilya Sutskever收集建立的一个用于普适物体识别的数据集。CIFAR是加拿大政府牵头投资的一个先进科学项目研究所。这个项目加速推动了Deep Learning的进程。数据集由十个类共60000张尺寸为32×32像素的彩色图像组成,其中每个类包含了6000张包含了标签的图像,同时整个CIFAR-10数据集还分为50000张训练集和10000张测试集。CIFAR-10数据集的最大特点是其作为一个普适性的数据集,较之前的只具有特定专业方向的数据集更有使用意义,用户群体更大。其姊妹数据集CIFAR-100更是将数据分类扩大到了100类。
CIFAR-10数据集的数据格式并不是单个的图像格式,而是将标签和图像数据二进制化分别存储,其存储格式为<1*label><3072*pixel>,首先是一个字节的空间存储label(标签),然后存放图像的数据,数据集对图像的尺寸没有具体限制,但要求所有的图像尺寸一致。如果图像为多个通道,则格式为label开头,之后分别存储RGB三个通道的数据。生成二进制格式的数据集的程序流程图如图3.5所示。
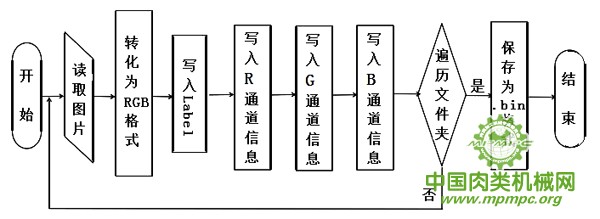
图 3.6 数据集二进制化程序流程图
3.5 本章小结
本章主要介绍了制作应用于猪胴体图像分级数据集的过程。以从九星集团猪肉加工流水线上采集到的图像为原始素材,通过图像增广扩大了数据集中的有效图像数量,通过 SMOTE 算法解决了数据集存在的样本不均衡问题,使用固定格式对图片进行命名,并通过针对深度学习的数据预处理方法对数据集进行了处理,为了方便未来的进一步研究,将数据集转化成标准的二进制格式。
《未完待续》
免责与声明
1.凡注明有“【独家】”的内容,其所有权均属“中国肉类机械网”所有。
2.凡转载本网“【独家】”内容,需与本网联系,并注明信息来源“中国肉类机械网”,违者将追究法律责任。
3.凡本网编辑转载的信息内容,旨在传递更多信息,并不代表本网赞同其观点和对其真实性负责。
4.如涉及作品内容、版权和其它问题,请在15日内与本网联系,我们将在第一时间删除内容并表示歉意!
5.版权&投稿热线:电话:010-88131969,传真:010-88131969,邮箱:mpmpcweb#126.com(注#换成@)
2.凡转载本网“【独家】”内容,需与本网联系,并注明信息来源“中国肉类机械网”,违者将追究法律责任。
3.凡本网编辑转载的信息内容,旨在传递更多信息,并不代表本网赞同其观点和对其真实性负责。
4.如涉及作品内容、版权和其它问题,请在15日内与本网联系,我们将在第一时间删除内容并表示歉意!
5.版权&投稿热线:电话:010-88131969,传真:010-88131969,邮箱:mpmpcweb#126.com(注#换成@)